Google offers OCR in two functional areas. The Cloud Vision API called TEXT_DETECTION detects and extracts text from any image, such as a photograph that might contain a street sign or traffic sign. The Document AI API called DOCUMENT_TEXT_DETECTION is designed for detecting text in scanned documents and is used in structured form parsing and entity extraction. The JSON output includes page, block, paragraph, word, and break information.
The Google Document AI suite includes pre-trained models for data extraction from specific document types and the Document AI Workbench to create new custom models or uptrain existing ones. The pre-trained models include a group of 4 General Processors, about three dozen Specialized Processors, and offers the ability to build and train new Custom Processors. Processor Limits define the maximum number of documents that can be processed via Synchronous and Asynchronous requests. For example, Document OCR limits include 10 pages for Synch and 500 pages for Asynch requests, while the limits for the Form Processor are 5 and 100, respectively.
The General Processors include the Document OCR to identify and extract text, the initial stage of data extraction from source images or PDF documents. The Form Parser extracts Key-Value pairs, tables, and a total of 11 generic entities (Email, Phone, URL, Date Time, Address, Person, Organization, Quantity, Price, ID, Page Number). The Intelligent Document Quality Processor assesses image quality and readability for defects such as blurry, noisy, dark, and faint. The Document Splitter is available for documents up to 30 pages to split logical documents.
The Specialized Processors are designed for document-specific data extraction. Some of these are broadly focused, such as the Pay Slip, Expense, and Invoice Parsers. Others are much more specific such as the US and French Passport Parsers, or those targeting specific forms such as 1040, 1099, W2 and so on. There are separate Splitter & Classifiers for Lending and Purchase Documents.
If customer documents match these Parsers, the data extraction process is simplified, but as we see below, further customization work may be required for optimum performance. The above-mentioned availability of so many focused parsers is a clue for people experienced in production data extraction that considerable customization is required. These Custom Processors in Document AI are called Custom Data Extractors (CDE). As the web site documentation explains: “You typically would use a CDE on documents that are all of one type.”
The Document AI web site offers comprehensive documentation and tutorials to make best use of the resources available. They provide a 12-step workflow to create and use a CDE. These steps begin with the creation of a CDE in the Document AI Workbench. After creating a dataset in a Cloud Storage Bucket, define and create the processor schema. Import documents to create Training and Test sets. Annotate the documents manually or with Labeling Tasks. Train, Evaluate and Deploy the Processor, and then of course, Test the processor. Configure Human-in-the-Loop (HITL) for review. And the final step is to use the processor on live documents in production.
While we are using different tools, all these tasks are familiar to anyone who has built traditional data extraction systems using legacy technologies. The extensive and easy-to-use public demo site for Document AI is the perfect launching point for evaluating how the off-the-shelf parsers perform on customer documents. Image and PDF input samples up to 5 pages can be tested, and in my experience there doesn’t seem to be a limit on how many samples you can submit. The Document AI demo is available at: https://cloud.google.com/document-ai.
The parsers available for testing at the demo site include: Document OCR, Form Parser, Document Quality, Invoice, Expense, Form 1040, Pay Slip, US Driver License, Identity Proofing and Contract. The extracted data available to examine varies with the parser chosen for testing. For example, if you choose the Document OCR test button, you have three options to view the response: OCR text, Document Quality schema, and JSON. Note: This JSON file contains OCR results with word location geometry and word confidence levels since this is simply the output of the Document OCR Processor. As with all the demo options, you can download the JSON file.
The Form Parser demo option provides more extensive insights into the capability of this General Processor. The output includes the ability to view: Key Value pairs, Tables, and Generic entities as well as OCR text and JSON output. The first three views immediately provide insight into the elements that will be recognized in your sample documents, but you will immediately notice that certain data on the page has not been categorized as Key-Value, Table or Generic entities. Clicking on the OCR text option will show that everything on the page (except in the poorest quality images) will have been recognized as text, but the text has not been extracted as structured data.
The Document AI Workbench is the platform where you can create custom ML models that match your specific needs. Uptraining allows you to start with a pre-built models and then use your own documents to label data fields and develop production models. Documentation, tutorials, and code samples are available on the web site.
Pricing is published on the Document AI site, with the General Processors priced at rates per 1,000 pages, with separate rates for up to 5M pages per month, and then 5M+. Specialized Processors are priced per 10 pages in a document.
The Extended Version of this analysis of Google Document AI includes multiple screenshots of the parsers in action with their resulting field identification. You can view the dee-dive version at my web site: https://DrApplebreath.com.
The Document AI Demo site allows public testing of customer documents in a variety of available Processors. The results of these tests provide an accurate analysis of both basic OCR functionality on specific images, as well out-of-the-box data extraction capability with different Processors. You need to set up an account to use the Demo site, but it comes with $300 free usage so you can accomplish significant amounts of testing and even early steps in development for free.
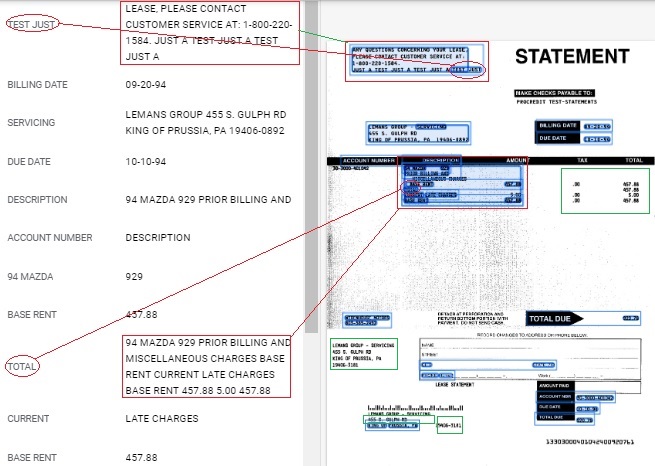
The screenshot below shows the results of using the Form Parser option on the Demo site to perform data analysis on a standard Statement type of document. All text on the page has been recognized by OCR, including White-on-Black text, as shown by choosing the OCR Text tab:

When you choose the “Key value pairs” tab, you see the results of the automatic data extraction using the generic Form Parser option in the Document AI demo site:
- The left side shows the Key Value Pairs automatically recognized.
- The right side shows the original form:
- Blue boxes and highlighted areas show automatically recognized data, both Keys and Values as displayed in resulting pairs on the left side
- Red ovals and red boxes show misrecognized Keys and Values; in the lower example the Key is the word “Total” in the red oval, and the Value is all the text in the red box.
- Green boxes show data that was accurately converted to text via OCR but was not recognized as Key Value Pairs.
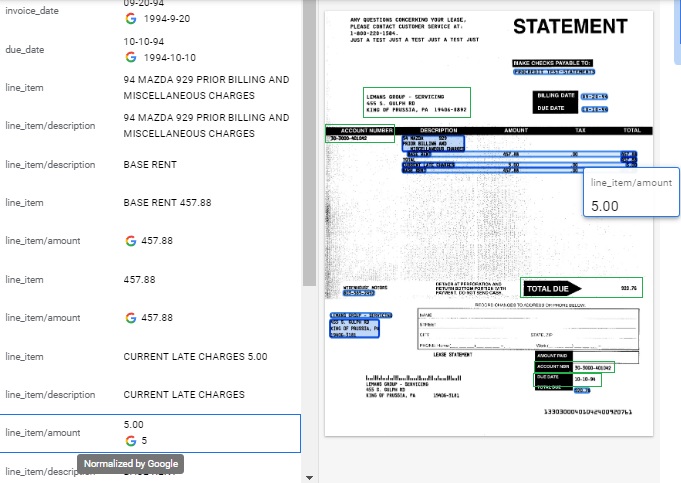
Using the same sample Statement image, but running it with the Invoice Processor option, we generate different results, demonstrating the parsing algorithms designed to recognize data in Invoice appearance documents:
- The left side shows the Invoice Schema automatically recognized.
- The right side shows the original form:
- Blue boxes and highlighted areas show automatically recognized data, both Schema and Values as displayed in resulting pairs on the left side.
- The green boxes indicate valuable data that was not recognized as part of the extracted Schema, including Billing Name and Address, Account Number, Total Due and Due Date.
- The colored “G” symbol represents data that has been normalized by Google with the “line_item/amount” selected on the left side and represented by the callout on the image display.
An example of a fully structured form is the Air Waybill below, a legally binding document that contains information on an international shipment including the contents of the shipment, the sender and recipient, terms and conditions, and other information. For our purposes of examining automatic data extraction, it is useful because most of the form fields contain a legend, or field name, in which the corresponding field value is entered. In Google Document AI terms, these two elements are called Key Value pairs. The below sample provides insight on the functionality of the generic Form Parser on the Demo site can do out-of-the-box. First, here is the top of the original TIFF input file.
Two areas of critical information on the Air Waybill are highlighted for further attention below:
- The first green box shows information at the top of the page which identifies three key data points: Airline Code Number, Airport of Departure, Air Waybill Number.
- The second green box shows Field Name “Consignee” and first three lines of actual Consignee’s address.

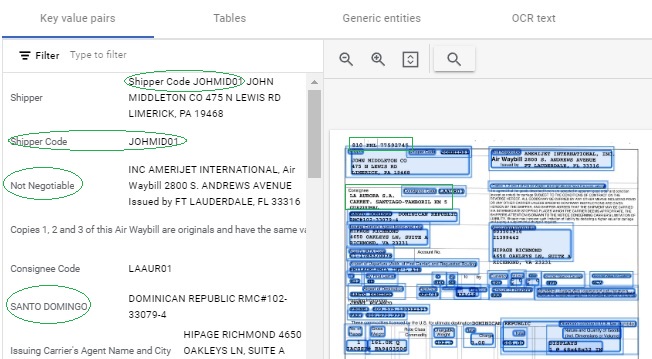
The screenshot below shows the output results of the Form Parser on the Document AI Demo site, with the “Key value pairs” tab selected to show that specific result. Again, the results are highlighted:
- The first green oval on left in “Key value pairs” column indicates both field Key “Shipper Code” and the Value which is the actual shipper code “JOHMID01” included as part of the Value for the Key “Shipper”.
- The second green oval shows properly recognized Key value pair for Shipper Code with both the Key and Value.
- Third green oval indicates text “Not Negotiable” improperly identified as a Key with useless text as Value.
- Fourth oval indicates another misrecognized Key with part of the address “SANTO DOMINGO”.
- On the right side, we see the original image with results of identified Key Value pairs.
- The first green rectangle includes crucial information that has not been recognized as part of a Key Value Pair, which means this data has not been usefully extracted even though it has been accurately recognized by the OCR process. This particular data includes three critical fields: Airline Code Number, Airport of Departure, Air Waybill Number.
- The second green value includes the unrecognized Key data “Consignee” as well as part of the actual consignee’s address Value that has not been extracted.
The Demo site provides not only an excellent opportunity to test customer documents but also provides the starting point for development of a production system. Given the results above, the next step would be to proceed to the 12-step process described above for building a Custom Data Extractor.
You have already created an account with Google to be able to use the Demo site, so now you have the option to log into the Document AI Workbench and begin the process of creating a CDE. Helpful Tutorials, Documentation and other materials are available to support your efforts. The free demo includes $300 in free credits to get you started.
PDF Expert – Master PDF and OCR
Copyright © 2023 Tony McKinley. All rights reserved.
Email: amckinley1@verizon.net