As described in the Textract Overview “Amazon Textract is a machine learning (ML) service that … goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables … and other data with no manual effort.”
Amazon offers OCR in two functional areas. The Amazon Rekognition API operation DetectText is different from DetectDocumentText. You use DetectText to detect text in live scenes, such as posters or road signs. Amazon includes OCR as part of the four Textract Analyze APIs.
Textract provides a total of five APIs, including the basic OCR API and four Analyze APIs. The Detect Document Text API extracts machine print and handwritten text. The call for synchronous operation is DetectDocumentText and is limited to processing single page documents. Asynchronous operation is called by StartDocumentTextDetection to process documents up to 3,000 pages with a 500 MB file size limit.
The Analyze APIs operate on the extracted text to identified structured data which is available as ZIP file output comprised of JSON files and various CSV files for various extracted data.
- Analyze Document API – extracts four features including Forms, Tables, Queries and Signatures which can be used together in any combination. Forms data includes key-value pairs. Tables extract data organized in rows and columns. Queries include responses to customer-created queries (e.g., Query: “What is customer name?” – Response: “Jane Doe”). Signatures detects and extracts handwritten and digital signatures.
- Analyze Expense API – extracts data from Invoices and Receipts such as Invoice ID, Invoice No., and other common features and their associated values using a standard taxonomy of 15 fields.
- Analyze ID API – extracts data from identity documents such as passports, driver licenses, etc. recognizing 21 standard fields including First Name, Last Name, Date of Birth, etc.
- Analyze Lending API – specialized for mortgage document processing to automate classification pages such as W2, Bank Statement, Check, etc. with splitting and extraction of results, including signature detection.
Amazon Textract can extract printed text, forms and tables in English, German, French, Spanish, Italian and Portuguese. Handwriting, Invoices and Receipts, Identity documents and Queries processing are in English only.
Amazon Textract produces .ZIP files named the same as the input file name as “InputName.zip” which depending on API can include .json, .txt and .csv files. For example, the Analyze Document ZIP file response includes a JSON file called “analyzeDocResponse.json”, “rawText.txt” and .csv files named “keyValues.csv”, “queryAnswers.csv” and “signatures.csv”.
Textract exports the recognized text with page geometry in the form of bounding boxes for each word retrieved, as well as a confidence value of 0 to 100 for each piece of data identified.
The Analyze Document API is designed to process a wide range of document types through three primary functions, the first two of which are Forms and Tables. The Forms feature extracts key-value pairs, while the Tables feature extracts tabular data. The third feature of the Analyze Document API is the Query function. This provides developers with the flexibility to specify the data they need to extract from documents using Queries without worrying about the structure of the data or variations in how the data is laid out across different formats and versions of the document. This approach is designed to find and extract key data such as “Vendor Name” or “Client ID” through natural language queries using words from the document to construct the queries.
The use of queries will be effective for classic forms that contain a pre-printed legend describing the Field Name so that the algorithm can identify the related Field Value. In this case the Field Name is the Key and Field Value is the Value that will be exported as output from the data extraction process. The Query approach will be challenged on documents that lack such pre-existing structure.
Queries are limited in number of queries per page. Synchronous operations allow a maximum of 15 Queries per page. Asynchronous operations allow a maximum of 30 queries per page.
A great source of quick insight into using these data extraction services is the public Amazon Textract Forum where you can review frequently encountered questions and responses. A typical question of not being able to recognize Key-Value pairs appears in the forum, and as suggested above, the response is “Can you try Queries? Ask “What is the Ship To address?” for example. A similar response is provided to the question “Is it possible to have custom field in AWS Textract Invoice to be extracted?” The reply is “You cannot train the Textract Analyze Expense model. Try Textract Queries of the Comprehend route.”
Amazon Comprehend is a separate approach and solution set beyond Textract designed to be applied to data extracted by Textract APIs. Comprehend uses Natural Language Processing to extract insights on entities, key phrases, language, sentiments, and other elements within documents. The Amazon Comprehend Console and Comprehend APIs are available for NLP applications which are traditionally considered to be separate from the data extraction functionality typically applied in forms and document processing applications.
Pricing is set per 1,000 pages processed, with the basic OCR of Detect Document Text API at a low cost. Analyze Document Pricing is separately available for data extraction via Queries, Tables, and Forms, as well as combinations of these functions. Signatures are available as a standalone price, with the feature included at no charge with any combination of Forms, Tables and Queries. The other three APIs, Analyze Lending, Analyze Expense and Analyze ID are separately priced.
The Amazon Textract Demo site, which requires account setup, is available at https://us-east-1.console.aws.amazon.com/textract/home?region=us-east-1#/demo. On the demo site you can use your own documents to test the Analyze APIs, including the Analyze Document, Analyze Expense, Analyze ID, and Analyze Lending. These first three APIs are limited to testing 100 pages per month, while the Lending API allows testing of 2,000 pages per month. The basic Detect Document API is limited to 1,000 pages per month.
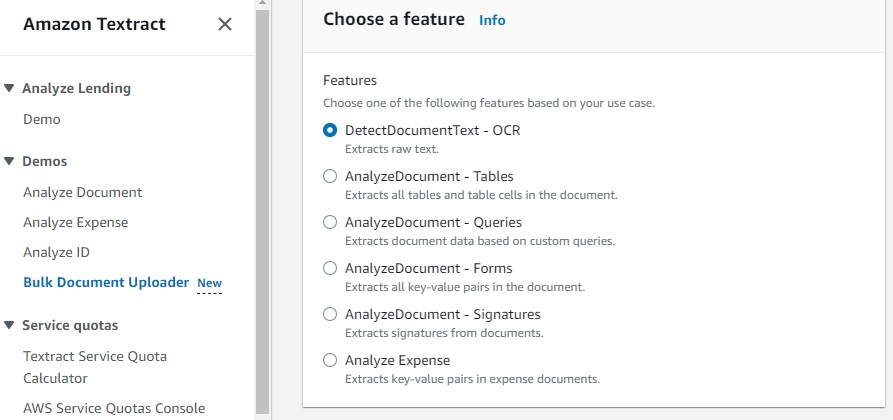
The Amazon Textract Demo site at allows public testing of customer documents on all APIs at https://us-east-1.console.aws.amazon.com/textract/home?region=us-east-1#/analyzelending/demo. From the Demo page, you can choose one of the four Analyze APIs, including Analyze Lending, Document, Expense and Lending. There is a new option to try the Bulk Document Loader, which appears to be the only way to test the standalone OCR functionality called Detect Document Test API.
The results of these tests provide an accurate analysis of both basic OCR functionality on specific images, as well as out-of-the-box data extraction capability with different APIs. You need to set up an account to use the Demo site, but you can start for free, and you can accomplish significant amounts of testing. You can also download the SDK and access developer resources.
The Analyze Document API is designed to recognize and extract four classes of data:
- Forms data includes key-value pairs.
- Tables extract data organized in rows and columns.
- Queries include responses to customer-created queries (e.g., Query: “What is customer name?” – Response: “Jane Doe”).
- Signatures detects and extracts handwritten and digital signatures.
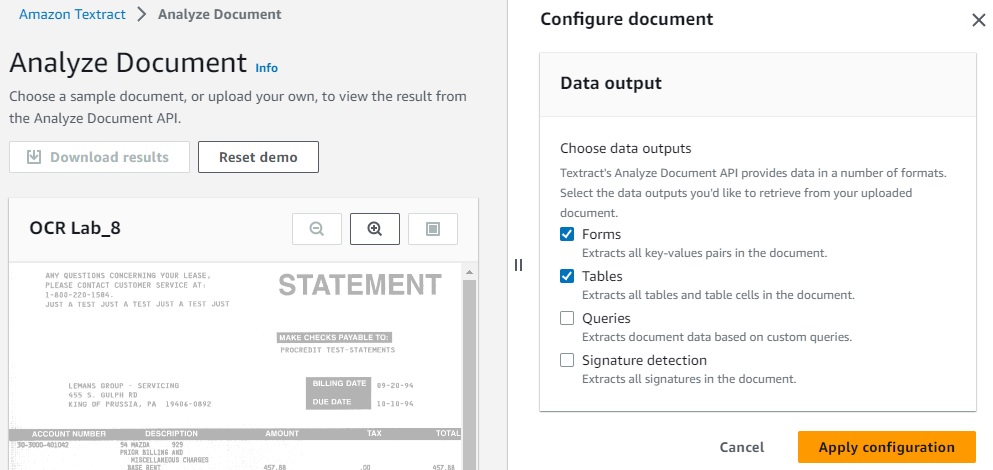
The screenshot below shows the result of this general-purpose API, with the Raw Text displayed on the right side. On the left side, the original image is displayed with overlaid recognized text areas.
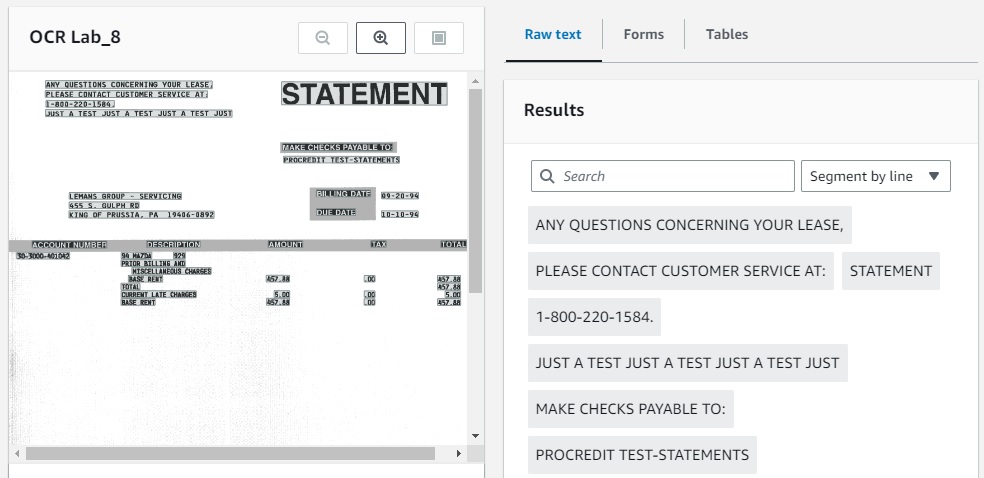
The same document processed by the Analyze Document is shown below with the Forms data tab selected.
- The recognized Key-Value Fields are highlighted on the left side with green boxes to indicate captured data.
- The right side displays the various Key Fields recognized as captions above the Value fields, in this case several are accurate and useful, meaning the data in the JSON output can be processed via an Accounts Payable process, for example.
- The accurately recognized Key Fields include Make Checks Payable To, Billing Date, Due Date and Total Due.
- Inaccurately recognized Key Field is shown as Widenhouse Motors, which is not a Key, and the corresponding Value is a Phone Number. This is an example of a data extraction error.
- An example of a Key Field created containing no captured value is the Name Field, another class of errors.
To demonstrate a relevant feature of the Analyze Expense API, the Tables tab has been selected below. This Table recognition is imperfect, but it looks promising. Since this sample image is a general example of a Statement, it represents a closer match to the Analyze Expense design intent to extract data from Invoices, Receipts, and similar documents.
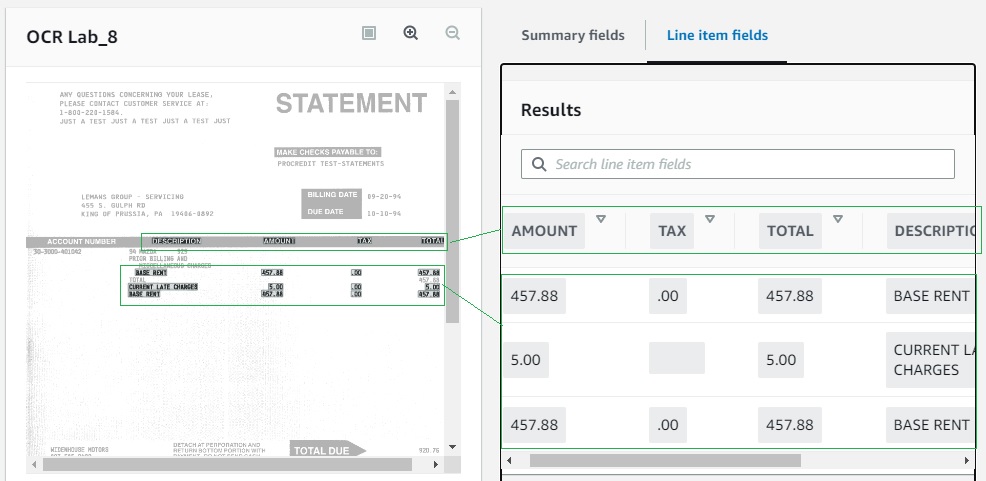
The screenshot below is an image of an international standard Air Waybill used to demonstrate a difficult challenge for this type of data extraction approach. The specific challenge is that some of the most critical information on this document appears at the top of the page with no pre-existing Field Name on the source form. The red box on the top left represents the Airline Code Number, Airport of Departure, and Air Waybill Number. But unlike other fields, such as those below with Field Names such as Shipper, Shipper Code, Consignee and so on, these top three items have no associated Field Names to identify them as Key-Value Pairs.

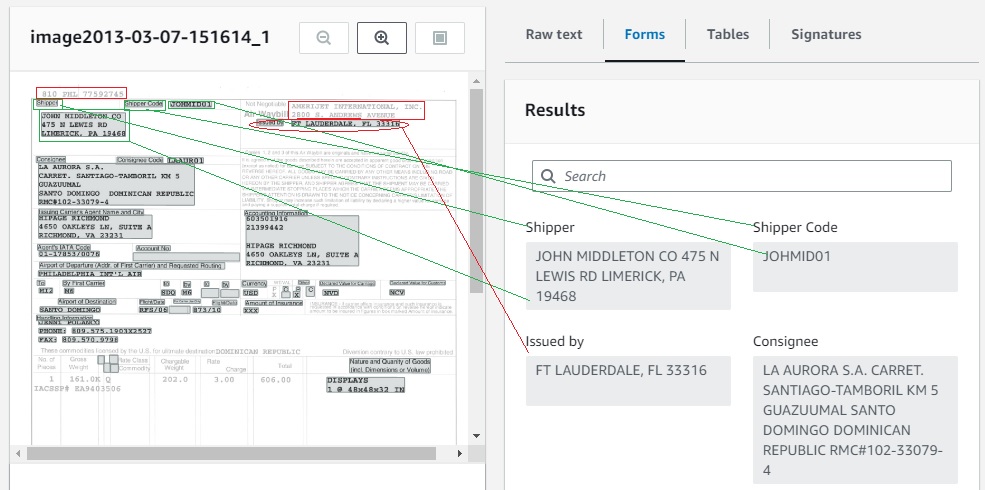
The screenshot below shows the results of processing the Air Waybill.
- The green boxes on the left side are overlaid on the image to illustrate Key-Value Pairs that have been successfully recognized and extracted. These include Key-Value Pairs of Shipper, Shipper Code and Consignee.
- The red boxes indicate important information that was not recognized as Key-Value Pairs including the critical Airline Code Number, Airport of Departure, and Air Waybill Number.
- The red box on the right is the Issued By organization, but the way the form is designed, it is very difficult to correctly identify the entire name and address.
- The red oval shows that the Field Name “Issued by” has been associated with the Field Value of “Fort Lauderdale, FL 33316”. On the right side, the Key-Value Pair generated is wrong and not useful for processing this data, so data extraction has failed with this data.
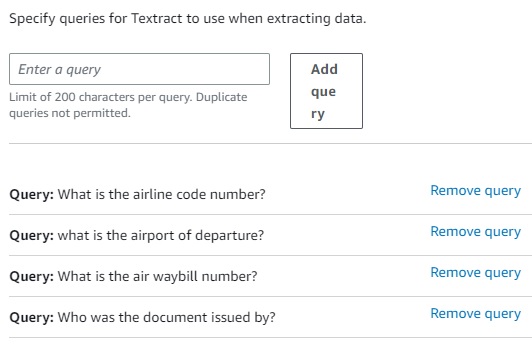
As mentioned above, the Amazon Textract Support response for issues like this is mentioned above. While you cannot modify the various APIs to extract specific data, you do have the option to try the Query method. A typical question of not being able to recognize Key-Value pairs appears in the forum, the response is “Can you try Queries? Ask “What is the Ship To address?”
In the screenshot below, I have followed the directions to attempt to use Queries to capture missed data elements by formulating Natural Language questions. But the fact that there is nothing on the page to indicate the Key corresponding to a Field Name means that a Query can’t find the information and generate a Key-Value Pair.
The following screenshot shows the CSV file with the responses to the above queries when applied to the Air Waybill sample. It’s not a surprise that the information cannot be identified, but it indicates a weakness in processing documents like this that lack specific structure recognizable by the Amazon Textract APIs. I suppose the solution would be to route this to Amazon Augmented AI (A2I) to send Amazon Textract output for review by humans. Output for review can be selected by Confidence Threshold or Random Review Percentage of documents.
In cases like this, it appears that all documents would have to reviewed by humans because the Confidence Threshold will not be precise enough to identify these types of fields, and the ALL documents will need to be reviewed, not a Review Percentage, since this type of data will not be recognized on any of these types of documents.

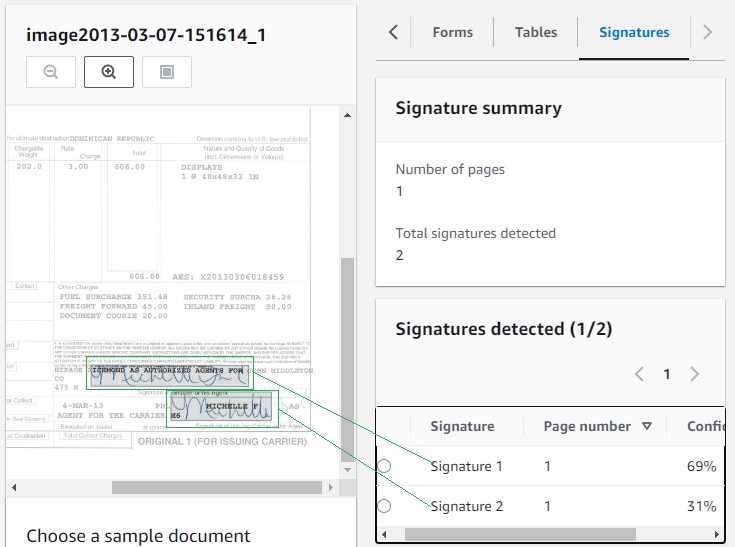
The screenshot below shows how Signatures, where they are handwritten signatures like these or digital signatures, are recognized, extracted, and output in both the JSON file and the corresponding CSV file included in the ZIP package.
The new Bulk Document Uploader demo feature is not meant to be used in production, you should use the standard APIs with live application.
What I find interesting it that is allows you get standalone OCR output from the Detect Document Text. The resulting .ZIP file contains three files, including the .JSON output of all files submitted with each job called “detectedDocumentTextResponse.json”, “rawText.txt” and “rawText.csv”.
- JSON file includes standard content of all recognized text, geometry location info confidence levels.
- TXT file includes plain text output which is handy for reviewing in Notepad or Word.
- CSV file includes spreadsheet comprised of four columns: Page Number, Type (LINE), Text, Confidence Score % (LINE).
Some observations of interest concerning the raw OCR output available from Detect Document Text API include the following:
- Test documents included 10-page PDF Image and Searchable PDF files.
- Test pages included low quality images imported from TIF files.
- Test pages comprised business faxes, multi-column documents including newspaper and magazine pages, scientific journal page with complex layout, business report with tables and standard and bulleted text.
- A total of 1,166 lines were recognized over ten pages, with an average Confidence Score % of 98.6% per Line.
- Text Columns and Page Sections are output in logical order, that is, the newspaper and magazine columns appear in the file one after the other in correct reading order.
- Tabular data is treated the same as text, so that the raw .TXT output of the Detect Document Text API is not useful for tables because the data appears sequentially, with the contents of original columns displayed without table structure. The .JSON file contains geometry information to theoretically allow reconstruction of tables.
In summary, the underlying OCR of Amazon Textract is extremely impressive across a broad range of samples, including very poor quality images. The sample documents used in this testing were specifically chosen to expose potential weaknesses in the data extraction algorithms in the various APIs. Source documents that better match the design parameters of the pre-built APIs can be expected to yield more useful results. The underlying weakness is the inability to modify the APIs when data appears in positions or without form field clues that allow identification as Key-Value Pairs, and the fallback of using Queries to find that type of data will often be insufficient for reliable recognition and extraction.
As in all OCR applications and forms processing production environments, the customer’s documents and how the data extraction system works on the customer’s data is the only thing that matters.
Copyright © 2023 Tony McKinley. All rights reserved.
Email: amckinley1@verizon.net