Microsoft offers OCR in two functional areas. Microsoft Computer Vision Read OCR is designed to process general, in-the-wild images. Form Recognizer Read OCR is designed to process digital and scanned documents. The JSON output includes recognized text, location of each text block, recognized language, and confidence for each text block.
Azure Form Recognizer is part of Azure Applied AI services that uses machine learning to extract key-value pairs, text, and tables from documents. Three general Document Analysis Recognizer Models are available, as well as five Pre-built Form Recognizer Models for specific document types. The Form Recognizer Studio is available to develop Custom Models for specific document types and Composed Models to combine multiple Custom Models. Processor limits include up to 2000 pages for PDF and TIF files, less than 500 MB total file size. In addition to standard image input, Azure Form Recognizer also extracts text from Microsoft Word, Excel, PowerPoint, and HTML documents.
The Form Recognizer models include the Read OCR Model which is designed to process generic documents such as letters or contracts to extract primarily text lines, words, locations, and detected languages. The Read OCR Model is also used in all the other models to create the text that is processed in subsequent handling. The General Document Model is pre-trained to support most form types and offers an alternative to training a Custom Model. The General Document Model extracts key-value pairs, selection marks, text, tables, and structure. It supports structured, semi-structured and unstructured documents. The Layout Model provides both Geometric and Logical Roles. Examples of geometric roles are text, tables, and selection marks. Examples of logical roles are titles, headings, paragraphs, page footers and page numbers.
A few Pre-built Form Recognizer Models are available including models designed to process W-2 Forms, Invoices, Receipts, Identity Documents and Business Cards. Each of these models is designed to capture specific types of information relevant to these document types. The Invoice Model extracts text such as customer name, billing address, due date and amount due. The Receipt Model extracts text such as merchant name, merchant phone number, transaction date, tax, and transaction total. The Business Card Model extracts first name, last name, company name, email address and phone number.
The Form Recognizer Studio is available to build Custom Models to match the extraction requirements of specific customer documents. A collection of Custom Models can be used together in a Composed Model, which are useful to apply several trained models to analyze similar form types. An example given is the use of a composed model to analyze supply, equipment, and furniture purchase orders. This potential relieves the requirement to select an appropriate model for a specific document type.
Up to 100 Custom Models can be combined into a Composed Model. In using this method, Form Recognizer classifies a submitted form and chooses the best-matching assigned model to return the appropriate results. Veterans of legacy forms processing technology will be familiar with this approach, which is traditionally referred to as Form Identification prior to applying a template for processing a specific document for data extraction. This type of approach can lead to considerable complexity in all areas, including initial training, model maintenance, quality assurance and human-in-the-loop intervention processes.
Custom Neural Models offer another approach to address this challenge where all the variations of a single document type are used in a single training dataset to train the neural model. This method is best suited for processing documents of diverse types for analysis and extraction. It is important to note that the definition of diverse types of documents includes variants of the same types.
Per Azure Form Recognizer documentation, a Custom Template or Custom Form Model relies on a consistent visual template to extract the labeled data. Accuracy is affected by variants in the visual structure of documents. It is recommended to train a model for each of the variants and then compose models into a single endpoint.
An overview of the process to create Custom Models begins with configuring a project from Studio home and using the wizard to enter project details. Begin with the labeling view and define labels and types to extract. Select the text in the document and select the appropriate label from the drop-down. Proceed for at least five documents. Use the Train command to start training with the selected model. Then use the Test command on test documents and observe the results. The labeling step is a demanding process to apply a labeled value to each field.
Pricing is available on a Pay-as-you-go basis or on Commitment Tiers. Pricing also varies according to whether you are using Connected or Disconnected Containers. Pricing is individually applied to Custom, Pre-built and Read Models.
The Azure Form Recognizer Demo site is available at Form Recognizer Studio – Microsoft Azure, but as noted above, you need to have an account set up first. On the demo site, you can test the Document Analysis Models including the Read, Layout and General Documents, and General Documents with Query Fields. You can test Pre-built Models including Invoices, Receipts, Business Cards and ID Documents. You can also test Health Documents, US Tax documents including W-2, 1098, 1098-E and 1098-T Tax Forms, as well as Contracts. You can also work with Custom Models, including Custom Extraction Models and Custom Classification Models. The site includes documentation to assist your explorations.
The Azure Form Recognizer Demo site allows public testing of customer documents in a variety of available Processors. The results of these tests provide an accurate analysis of both basic OCR functionality on specific images, as well as out-of-the-box data extraction capability with different Models. You need to set up an account and project to use the Demo site, but you can start for free, and you can accomplish significant amounts of testing and investigate initial stages of development.
Starting at the Form Recognizer Studio at Form Recognizer Studio – Microsoft Azure, you have options to choose the Demo versions of the three general models including Read, Layout and General Documents, while a Private Preview Sign-up is currently required to try the General Documents with Query Model. You can also choose any of six Pre-built Models (described above), while Private Preview Sign-up is required for the three 1098 Tax Form and Contract Models. You can freely create Custom Extraction and Custom Classification Models.
In the screenshot below, the General Document Model has been selected and a generic scanned Statement has been loaded for testing. Note that the visible poor image quality does not degrade OCR accuracy in this sample.
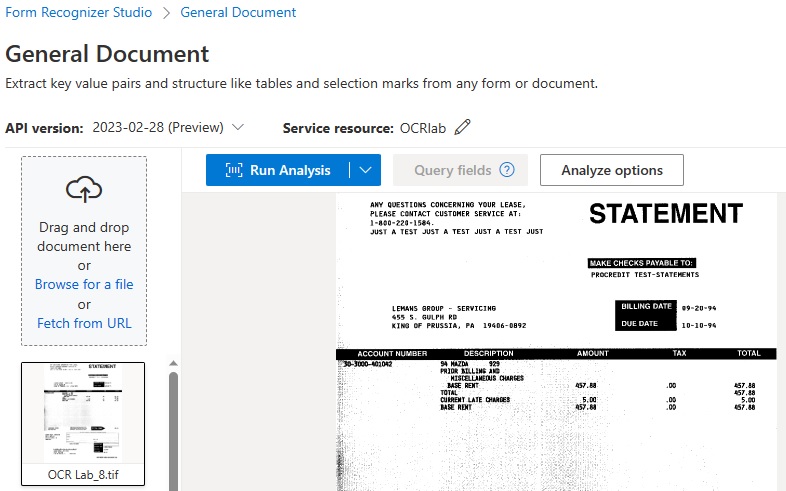
In the following screenshot, we see the result of the General Document Model analysis:
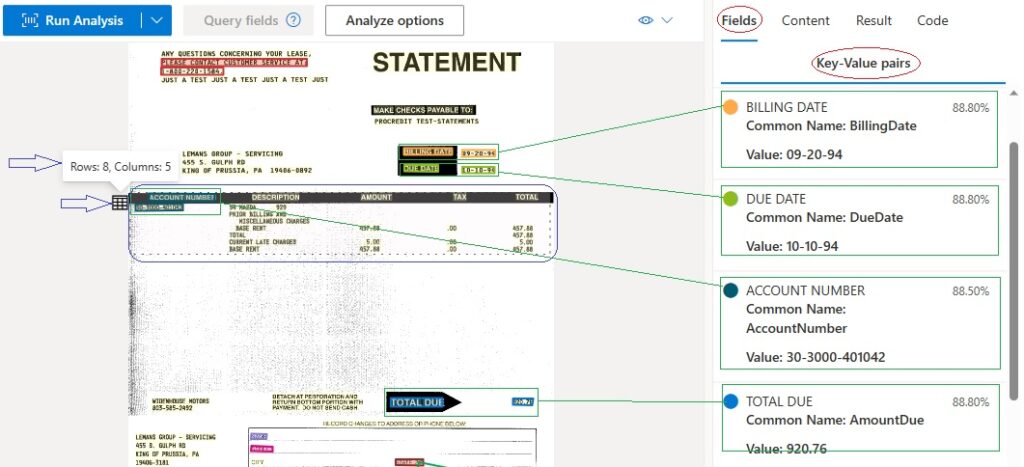
- Image area on the left, optional data areas displayed on the left include Fields, Content, Result and Code, with Fields selected.
- Yellow highlights indicate that all text has been recognized by OCR, including white on black.
- Color-coded areas on the image on the left correspond to Key-Value Pairs displayed on the right.
- I added green and blue outlines to display areas of interest.
- Green boxes on Image correspond to extracted Key-Value Pairs on the Data display. For the areas captured, the Model has done well in recognizing both the Key of the field and the Value in the field.
- The blue outline arrows and box indicate a Table identified by the General Document Model, which may be useful for subsequent processing. For example, an Accounts Payable process may require extraction and coding of the Line Items, including Product/Service, Item Amount, Tax and Extended Total.
To test a Pre-built Processor, the following screenshot shows the results of the Form Recognizer model: Invoice. The included description of the goal of this Processor is documented on the demo page as quoted below.
“Combine Optical Character Recognition (OCR) capabilities with deep learning models to analyze invoices of various formats and quality including photos, scanned documents, and digital PDFs. Extract key information such as customer name, billing address, due date, and amount due into a structured JSON data format. English and Spanish invoices are supported.”
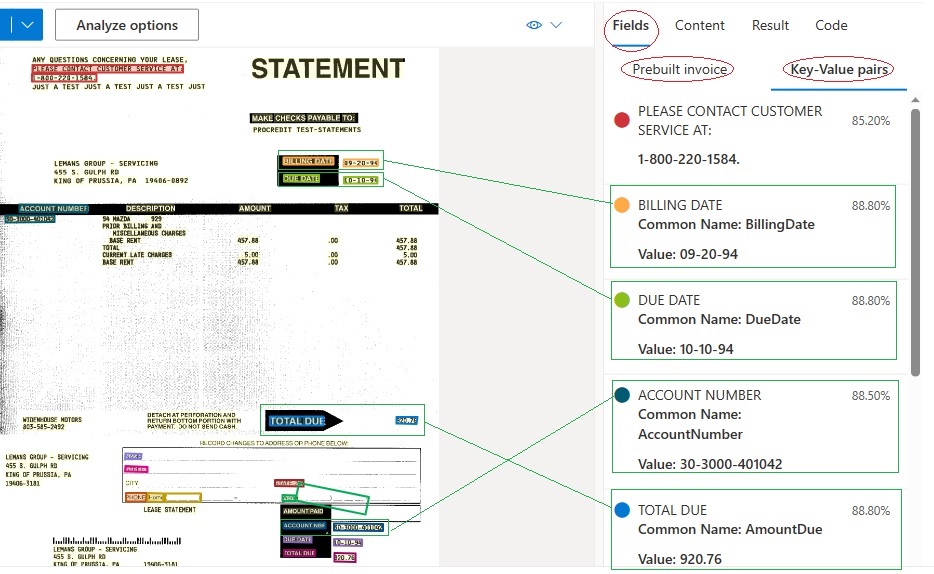
In the above examples, we note that both the General Document and Pre-built Invoice Models perform well when each field is clearly identified by Key Label, or Form Field Name. This provides insight on the way the ML works by using expected terms such as Billing Date, Account Number and Total Due to identify critical information in structured such as forms, and semi-structured documents like invoices, statements, etc.
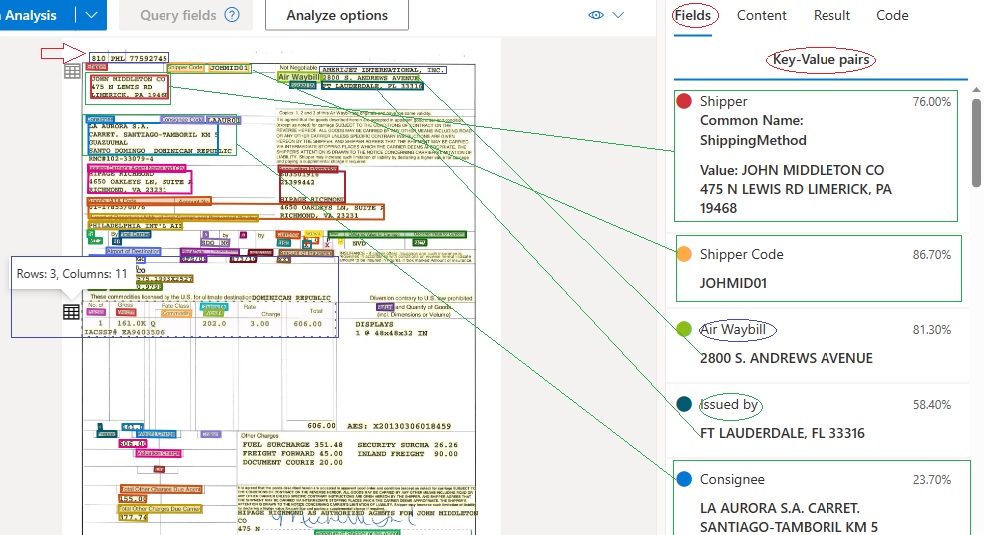
The example below is an international standard Air Waybill, which is both highly structured with Field Names to identify Key-Value fields, the document itself is the primary way to track and verify the shipment and receipt of goods. In the screenshot below, the original TIFF image of the document is shown with a few key areas of interest.
- The top box on left of the form indicates three crucial bits of information: the Airline Code Number, Airport of Departure, and Air Waybill Number. But unlike other fields, such as those below with Field Names such as Shipper, Shipper Code, Consignee and so on, these top three items have no associated Field Names to identify them as Key-Value Pairs.
- The two boxes on the right side of the form include what ML might assume to be target Key terms to use to identify information, but as we will see below, the placement of the Information and field names, or rather the Value and the Key info, causes confusion for automatic identification as Key-Value Pairs.

In the screenshot below, the markup is used to explain challenges to automatic data extraction on this important type of form:
- The red arrow at the top left points to text that has been recognized accurately by OCR, but it has not been characterized as data in a Key-Value Pair, because there is no Field Name to indicate. A Custom Model will need to be developed to recognize this information as the Airline Code Number, Airport of Departure, and Air Waybill Number. The traditional approach to this would be to simply identify this area of the page, measured in pixels from the top left edge of the page, and then programmatically look for three series of three digits, three digits and eight digits.
- The green boxes on the left side image and the right side extracted data in Key-Value Pairs indicate where the expected pattern has worked as designed. The Field Names of Shipper, Shipper Code and Consignee have been accurately applied to the recognized data, providing useful information for further processing.
- However, in other areas of the input document, whether due to the poor design, poorly placed filling of the original form, what should be Field Names are mixed in with Field Values to deliver inaccurate data extraction results.
- These inaccurate results result in Key-Value Pairs such as “Air Waybill – 2800 S. Andrews Avenue” and “Issued by – Ft Lauderdale, FL 33316.”
These examples suggest the classes of imperfect field and data extraction results one can expect and provide the reason Custom Models will need to be designed. The fact that it is also possible to develop Composed Models which are comprised of up to 100 Custom Models provides insight into the potential complexity of the issues large scale production environments can expect to encounter when processing wide varieties of forms and variants of forms.
PDF Expert: Master PDF and OCR
Copyright © 2023 Tony McKinley. All rights reserved.
Email: amckinley1@verizon.net