I have posted this article based on my two decades working with the largest law firms in the world. This article details the extensive user testing and evaluation process required to serve the world’s most demanding PDF users.
Searchable PDF documents are widely used in the practice of law whenever scanned paper files need to be entered into Document Management Systems because of the unique value they provide. The scanned image of paper pages provides an exact facsimile of the original, including elements such as signatures, stamps and drawings that can’t be converted to letters and numbers. OCR converts images to text, allowing rapid search and retrieval across large collections. Searchable PDF preserves both the original appearance on the visible Image layer, as well as the textual content in the Hidden Text Layer.
Theoretically, if the text is searchable, critical information will be found and critical documents will be retrieved. This provides the undeniable value that documents can be retrieved through text search, without the additional labor and expense of indexing each document to tag critical information for future retrieval. But conventional search based on exact match of query and target terms, is absolutely dependent on the accuracy of the OCR-created text layer.
As everyone who has ever converted a scanned document to text knows, we must always assume that OCR results are NEVER perfect. PDF Editors offer an OCR Proofreader, an image-assisted process similar to a spell-checker. If we invest the labor and expense of reviewing and correcting OCR results, the text search results will be highly reliable. But most organizations do not invest the effort to correcting OCR errors in Searchable PDF because mis-recognition errors only appear in the Hidden Text Layer, people can still read the Image layer. The vast majority of Searchable PDF is produced via scanning with OCR whether via network MFP, dedicated scanners or service bureaus with none of the proofreading available in PDF editors.
Modern OCR is extremely accurate, but poor image quality will cause errors in recognition. Multi-generation copies, faxes and even skewed scans can cause errors. Characteristics of the text itself, such as odd fonts, italics or the underlines on forms that touch and join the characters of the text all can cause misrecognition.
Beyond pure character recognition, OCR uses dictionaries to aid accuracy by confirming identified text with common words. Unfortunately, this method is limited because it cannot help with Proper Names and Numbers. And we know that the most critical information in documents typically appears in Proper Names and Numbers.
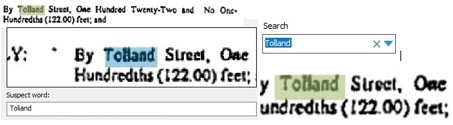
The left side of the image at the top of this article provides an example of a Proper Name displayed in the Proofreader. In this case the street name “Tolland” has been recognized as “Toliand” due to poor image quality of the original document. If this OCR mis-recognition occurred in the only instance of the one critical search term we are using to try to find this document, this document goes unfound.
So, what’s the solution? How can we achieve the best possible results when working with Searchable PDF documents created with fallible OCR? Fuzzy Search provides the best solution at lowest cost.
The right side of the image at the top displays the Search screen, where the query is “Tolland” and the hit highlight appears on the imperfectly recognized search term.
In my book “From Paper to Web” (Adobe Press, 1997), I explained the concept:
“Fuzzy Search may be thought of as a form of automated wild card searching. Fuzzy Search is designed to find imperfect occurrences of the query term, and this is accomplished by a very smart software algorithm that substitutes wild cards for each of the characters of a query term.
A Fuzzy Search for the term “search” might be thought of as multiple wild card searches such as “?earch,” “s?arch,” “se?rch,” “sea?ch,” “sear?h,” and “searc?.” Such a multiple wild card search, which will find every occurrence where any one of the characters in the term is missing, is equivalent to a Tight Fuzzy Search. Correspondingly, a Loose Fuzzy Search would make allowances for more missing characters in the string.
The value of Fuzzy Search is that the user doesn’t have to enter a different search term for each exact occurrence the target term.”
Because Fuzzy Search doesn’t require an Exact Match, but only a Close Match, we may find the document using imperfect, uncorrected OCR-generated text. Fuzzy Search has highlighted the Search Result when we are looking for “Tolland”, even though the Hidden Text layer is actually recognized as “Toliand”.
All web search engines use variants of fuzzy search by either suggesting alternative query terms or simply returning irrelevant results you are not looking for. Fuzzy search is generally not found in document management systems, although wild cards provide a more laborious alternative. DMS plug-ins are available to fill this gap. PDF editors offer wildcard search and pattern search (SSN, Date, Phone, Credit Card) but Fuzzy Search is only available in Kofax Power PDF.
Fuzzy Search can be thought of as the OCR of Search, that is, neither OCR nor Fuzzy Search can ever be thought to be perfect and 100% accurate. But just like OCR, Fuzzy Search promises to be a huge time and labor saver, and a vast improvement over the alternatives. The alternative to OCR is typing, the alternative to Fuzzy Search is either expensive manual indexing or expensive OCR Proofreading. By providing the ability to find search results within imperfectly OCR-ed text, Fuzzy Search is the perfect complement to work with Searchable PDF documents.
By Tony McKinley
Author of “PDF Expert – Master PDF and OCR”
Former Lead PDF SE for ScanSoft/Nuance/Kofax
Web with Preview chapters of “PDF Expert”, complete PDF of “From Paper to Web”, articles on Google/Amazon/Microsoft Data Capture, ChatGPT:
Available on Amazon: https://www.amazon.com/PDF-Expert-Master-OCR/dp/B0BZC1515S/ref=sr_1_1?crid=D9P2HY1ZGBDK&keywords=PDF+Expert&qid=1680465943&s=books&sprefix=pdf+expert%2Cstripbooks%2C103&sr=1-1