Kofax Power PDF, at the time of this writing, is the only PDF Editor that offers Fuzzy Search. In the field of Information Retrieval, this powerful search methodology has been available for decades.
In my book “From Paper to Web” (Adobe Press, 1997), I explained the concept this way:
“Fuzzy Search may be thought of as a form of automated wild card searching. Fuzzy Search is designed to find imperfect occurrences of the query term, and this is accomplished by a very smart software algorithm that substitutes wild cards for each of the characters of a query term.
A Fuzzy Search for the term “search” might be thought of as multiple wild card searches such as “?earch,” “s?arch,” “se?rch,” “sea?ch,” “sear?h,” and “searc?.” Such a multiple wild card search, which will find every occurrence where any one of the characters in the term is missing, is equivalent to a Tight Fuzzy Search. Correspondingly, a Loose Fuzzy Search would make allowances for more missing characters in the string.
The value of Fuzzy Search is that the user doesn’t have to enter a different search term for each exact occurrence the target term.”
To understand the concept visually, Figure 14.5 provides examples of how Fuzzy Search might perform. The concept is that Fuzzy Search identifies not just Exact Matches but Close Matches. In this example, the Search Term is “Boolean”. The highlighted Hits represents the result of Fuzzy Search. You can see that Exact matches of the Search Term are highlighted, as well as Close matches. In this example, Search Hits are identified where 1 of 7 and 2 of 7 characters do not match the characters in the Search Term. Notice that when the match becomes too inexact, that is when 3 or 4 of 7 characters do not match the characters in the Search Term, no Hit Result is produced. This is because Fuzzy Search will soon hit the limit of diminishing returns, where too many inappropriate potential hits might be identified. When this limit is reached, and excess of false hits becomes a waste of time and labor.
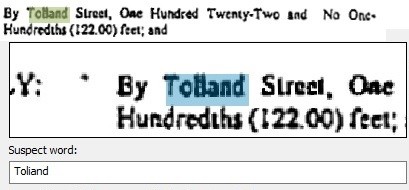
The greatest potential advantage of Fuzzy Search is when we are working with Searchable PDF, that is scanned images that have been processed to add a Hidden Text Layer. Figure 14.6 below originally appeared in Chapter 10 – Conversion and OCR in the context of our discussion of the OCR Proofreader which is applied to the results of the Make Searchable process.
The value of Searchable PDF is that large collections of scanned documents can be indexed and valuable documents can be retrieved through text search, without the additional labor and expense of skilled staff reviewing and indexing each document to tag critical information for future retrieval. Theoretically, if the text is searchable, critical information will be found and valuable documents will be retrieved.
This takes us back to Rule #1 of OCR: Always assume that OCR results are NEVER perfect. And that brings us to the value of the OCR Proofreader, if we invest the labor and expense of reviewing and correcting OCR results, the text search results will be highly reliable. But how many people or organizations invest the effort of correcting OCR errors in Searchable PDF? That’s a rhetorical question.
There are ways to reduce the time and labor of proofreading, assuming skilled professional operators are doing the work. We know that OCR has the most difficulty with words that do not appear in the recognition dictionary, which includes Proper Names and Numbers. And we know that the most critical information in documents typically appears in Proper Names and Numbers, professional reviewers can be theoretically trained to only correct this critical information. Another rhetorical question – how many people do that?
So, what’s the solution? How can we achieve the best possible results when working with Searchable PDF documents created with fallible OCR? Fuzzy Search provides the best solution at lowest cost.
Figure 14.6 provides an example of a Proper Name displayed in the Proofreader. In this case the street name “Tolland” has been recognized as “Toliand” due to poor image quality of the original document that was scanned. If this OCR mis-recognition occurred in the only instance of the one critical search term we are using to try to find this document, this document goes unfound. Now, if we invest the time and labor in using the OCR Proofreader, problem solved, the Hidden Text is corrected to “Tolland” and the subsequent search for “Tolland” finds the critical document.
Alternatively, we use Fuzzy Search on the uncorrected document, errors and all. Because Fuzzy Search doesn’t require an Exact Match, but only a Close Match, we may find the document use imperfect, uncorrected OCR-generated text.
Fuzzy Search has highlighted the Search Result when we are looking for “Tolland”, even though the Hidden Text layer is actually recognized as “Toliand”.
Fuzzy Search can be thought of as the OCR of Search, that is, neither OCR nor Fuzzy Search can ever be thought to be perfect and 100% accurate. But just like OCR, Fuzzy Search promises to be a huge time and labor saver, and a vast improvement over the alternatives. The alternative to OCR is typing, the alternative to Fuzzy Search is either expensive manual indexing or expensive OCR Proofreading.
PDF Expert – Master PDF and OCR
Copyright © 2023 Tony McKinley. All rights reserved.
Email: amckinley1@verizon.net